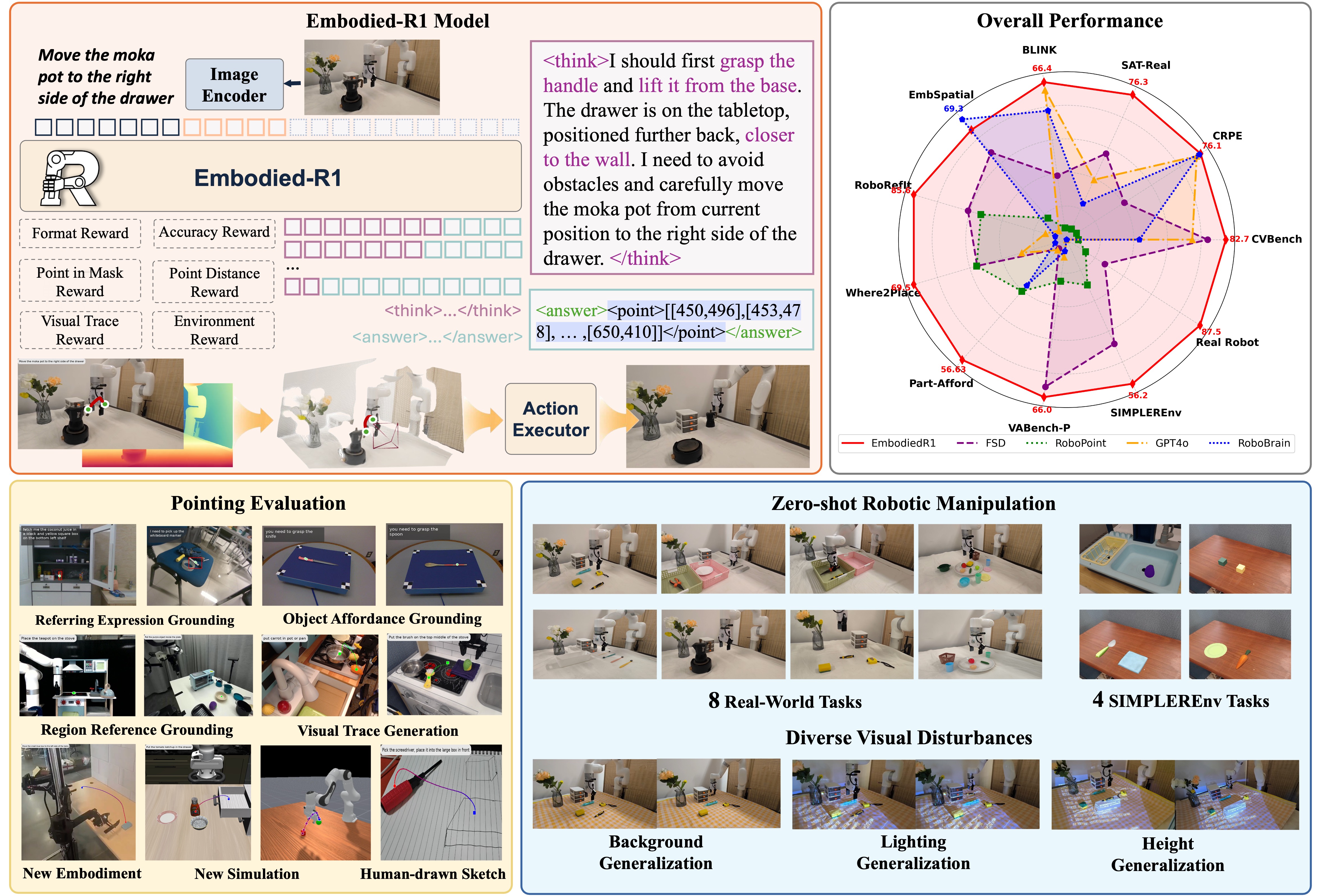
Overview of Embodied-R1 Framework. Embodied-R1 is a 3B vision-language model (VLM) designed for general robotic manipulation. Through an innovative "Pointing" mechanism and Reinforced Fine-tuning (RFT) training methodology, it effectively bridges the "seeing-to-doing" gap in robotics, achieving remarkable zero-shot generalization capabilities.
Results
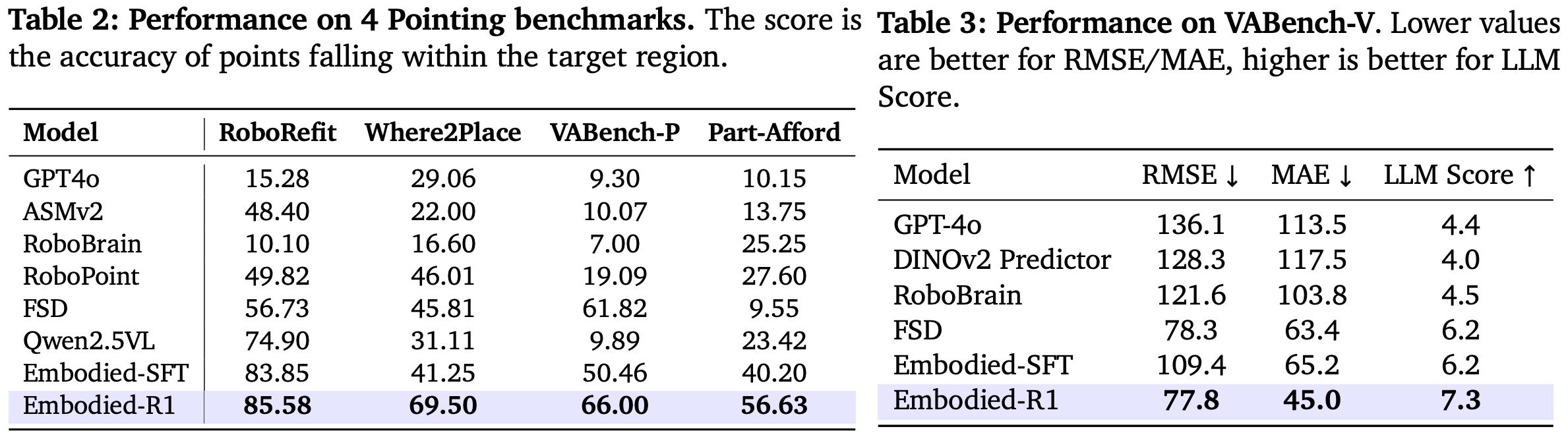
Real-world Robot Manipulation Demonstrations
Embodied-R1 demonstrates superior performance in real-world robot manipulation tasks, achieving an 87.5% success rate across 8 diverse tasks in a zero-shot setting. Below are visualizations of the model performing these tasks.
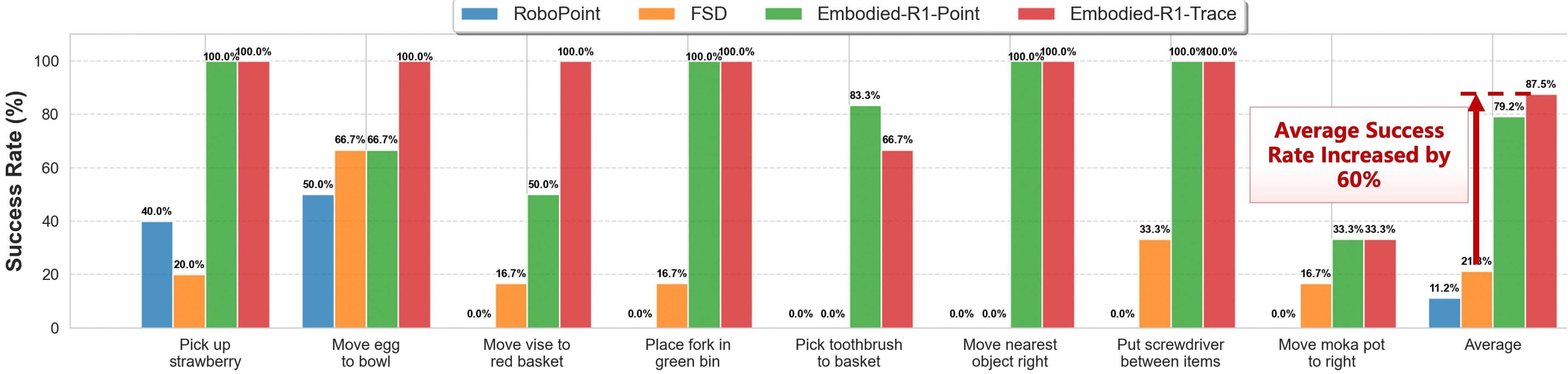
Real-world experimental evaluation results.
Task 1: Pick up the strawberry
Task 2: Move the egg to the bowl
Task 3: Move the vise to the red basket
Task 4: Place the fork in the green bin
Task 5: Pick the [x] toothbrush and place it to the bucket
Task 6: Move the nearest object to the right side of the drawer
Task 7: Put the screwdriver between drawer and the vase
Task 8: Move the moka pot to the right of drawer
Visualization of Performance on Various Pointing Tasks
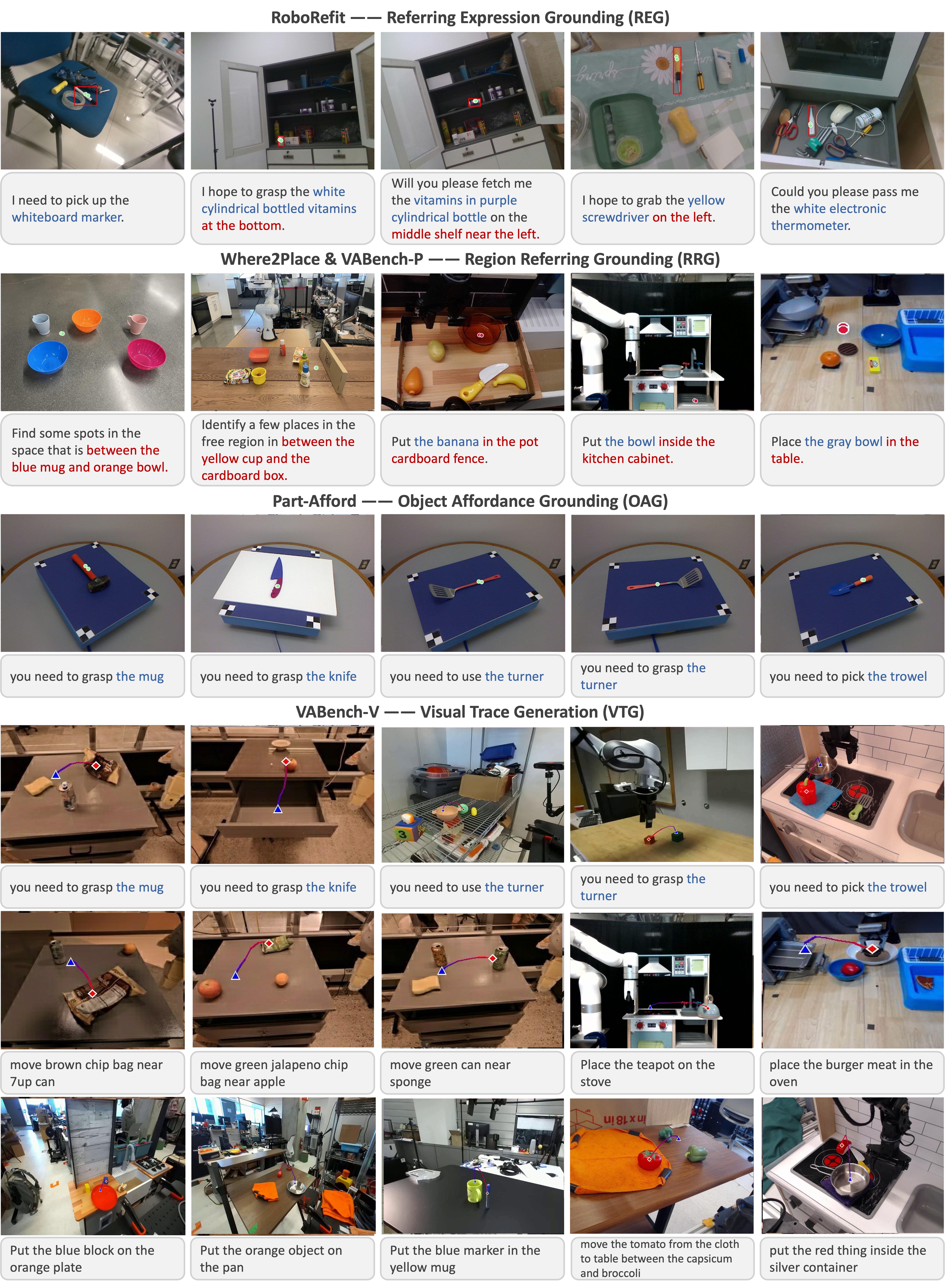
Visualizing Embodied-R1's Performance on Various Pointing Tasks. The model can follow diverse text instructions and generalize its capabilities to novel, unseen environments.
Robustness to Visual Disturbances

Embodied-R1's performance under different visual disturbance conditions. The model maintains 100% success rate under original conditions and background changes, with 83% success rate under combined background, light, and height changes.
Original
Background Change
Background+Light Change
Background+Light+Height Change
The process of Embodied-R1 performing Task 6 under different visual disturbances.